- PBFT - Practical Byzantine Fault Tolerance
- BFT
- PBFT 的重要概念
- PBFT 的大致流程
- Fault 的分类
- 为什么达成 Prepared 状态需要 $2f+1$ 个 Matching
- Commit Phase 的必要性
- 为什么达成 Committed 状态需要 $2f+1$ 个 Prepared
- 为什么 New Primary 需要 $2f$ 个 View Change
- 为什么 Reply 需要 $f+1$ 个 Matching
- Checkpoint (Garbage Collection) 的必要性
- Checkpoint 为什么在数字签名模式下只需要 $f+1$?
- View Change 和 Liveness 之间的关系
- Primary 作恶带来的 In-Dark 问题
- Network Recovery 的流程
- Misc
PBFT - Practical Byzantine Fault Tolerance
论文链接:https://pmg.csail.mit.edu/papers/osdi99.pdf
BFT
BFT (Byzantine Fault Tolerant) 拜占庭容错,指的是在一个分布式系统当中,在有节点可能出现任意行为(包括但不限于崩溃、发送错误数据、出现恶意行为等)的情况下,仍可以正常运行即达成共识。
PBFT 的重要概念
PBFT 可以保证在一个大小为 $3f+1$ 的分布式网络下,容忍至多 $f$ 个节点的拜占庭错误。
- Primary (Leader): PBFT 是一个 leader-based 的协议,即在任意时刻,都有一个 leader 主导协议的走向。
- 视图 View: 在 Primary 不发生改变的一段时间我们称之为 View。注意到:View 的编号是单调递增的。给定一个视图编号 $v$,我们就可以唯一确定这个视图的 Primary 编号 $p = v \bmod |\mathcal R|$,其中 $\mathcal R$ 是所有节点的集合,即所有 Replica 的集合。
- Replica: 可以理解为服务器节点。
- 目标: 达成 Consensus。即在每一个 Replica 上,所有的 transaction 内容和顺序都保证一致。
- View Change: 视图改变。正因为协议由一个 Leader 主导,那在 leader 出现 malicious behaviour 的时候,协议可以保证触发 View Change,即更换 leader,来保证 liveness。具体内容后文会详细说明。
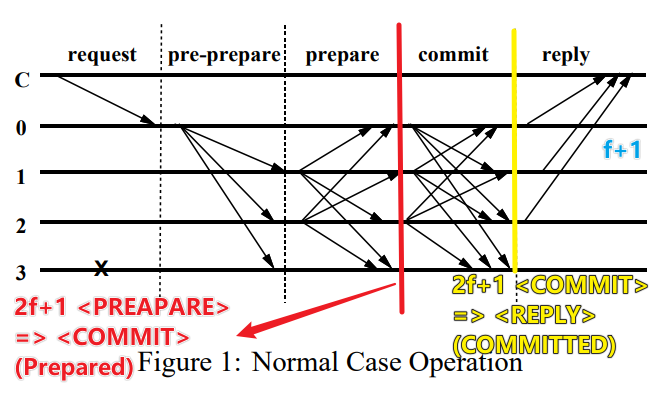
PBFT 的大致流程
Normal Case Operation 即 Primary 不出问题的情况下

- [REQUEST] 客户端向 Primary 发送 $\langle Request, o, t, c \rangle _{\sigma_c}$ 请求
- $o$: Operation
- $c$: Client
- $t$: Timestamp - 这是用来保证执行的 exactly-once semantics
- [PREPREPARE] Primary 将请求 Multicast 给所有 Replica: $\langle \langle Preprepare, v, n, d \rangle _{\sigma_p}, m \rangle$
- $v$: view
- $n$: Primary 给这个请求分配的 Sequence Number 【关于 Sequence Number: 一个正常的 Replica 只会按顺序 (Sequence Number) 处理消息。即若其收到了 127 号消息但始终没有收到 125、126 号消息,127 号消息便一直不会处理。】
- $d$: $d = D(m)$ 消息 $m$ 的 digest (摘要)
- [PREPARE] 每个 Replica $i$ 收到请求之后,如果选择接受请求(原文有更详细的描述),就会向所有 Replica 广播 Prepare: $\langle Prepare, v, n, d, i \rangle _ {\sigma_i}$
- [COMMIT] 接下来,如果每个 Replica $i$ 收到了其他 Replica (包括自己在内) 一共 $2f+1$ 个 Prepare 请求,这个时候认为其进入了 Prepared 状态,并广播 Commit 消息: $\langle Commit, v, n, d, i \rangle _ {\sigma_i}$
Checkpoint Protocol
见原文,不赘述。
View Change Protocol
- 在怀疑 Primary 作恶的情况下,Replica 会广播 View Change 消息: $\langle ViewChange, v+1, n, \mathcal C, \mathcal P, i \rangle _{\sigma_i}$
- $\mathcal C$ 是用来证明上一个 Checkpoint 的有效性的
- $\mathcal P$ : 对于所有编号在 $n$ 之前,上一个 Checkpoint 之后的消息 $m$,$\mathcal P_m \in \mathcal P$,其中 $\mathcal P_m$ 包含了 $m$ 的 Preprepare 消息和 $2f+1$ Matching。
- 注意到之所以包含了这么多消息,主要就是为了防止消息伪造,全部演算一遍数字签名,出现纰漏就直接忽略,拒不执行。
- 如果一个 Replica 收到了 $f+1$ 个 View Change 请求,那他也会广播 View Change 请求,加速 View Change 进程。
- New Primary 收到 $2f$ 个 View Change 请求之后(不包括自己),广播 $\langle NewView, v+1, \mathcal V, \mathcal O \rangle _{\sigma_i}$,具体的计算细节原文写的很详细了。
Fault 的分类
见:https://dinhtta.github.io/pbft/
Network Failure Model
Byzantine fault tolerant protocols tolerate at most $f$ Byzantine failures. In a distributed system, however, there are two types of failures: node and network. It is important to distinguish them, especially since they determine guarantees about the protocol’s safety and liveness.
Node failure means a node (or server, peer, entity, etc.) behaves arbitrarily. This captures the strongest adversary model. A network failure refers to network partitions which can last for an unbounded amount of time. It can be quantified as the number of nodes being isolated from the rest of the network, although they can still communicate with each other.
Given this distinction, what are being counted toward $f$? In PBFT
- $f$ refers to node failures. The protocol guarantees safety upto $f$ node failures. Safety is independent of network failure. That is, even if the network is severely partition, namely more than $f$ nodes are isolated (but across all partitions there are still fewer than $f$ node failures), the protocol is still safe.
- However, liveness is only guaranteed with fewer than $f$ total failures, i.e. counting both node and network failures. This means at least $2f+1$ nodes must be reachable.
Note that safety being independent of network failures is a strong guarantee, and it is common in most variants of PBFT. Not until Liu et al. recent work, namely XFT, is it relaxed in a way that separates out node and network failures.
为什么达成 Prepared 状态需要 $2f+1$ 个 Matching
Prepared 保证了什么?
要回答上面的大问题首先要理解我们想要 Preprepare + Prepare Phase 保证什么。论文 Section 4.2 已经回答了这个问题,即
$$
prepared(m, v, n, i) \Rightarrow \lnot prepared(m', v, n, j), \forall i,j,m,m', s.t. D(m') \neq D(m)
$$
即我们要保证在同一个 view 内,每一个 sequence number 只对应唯一一个 prepared message。
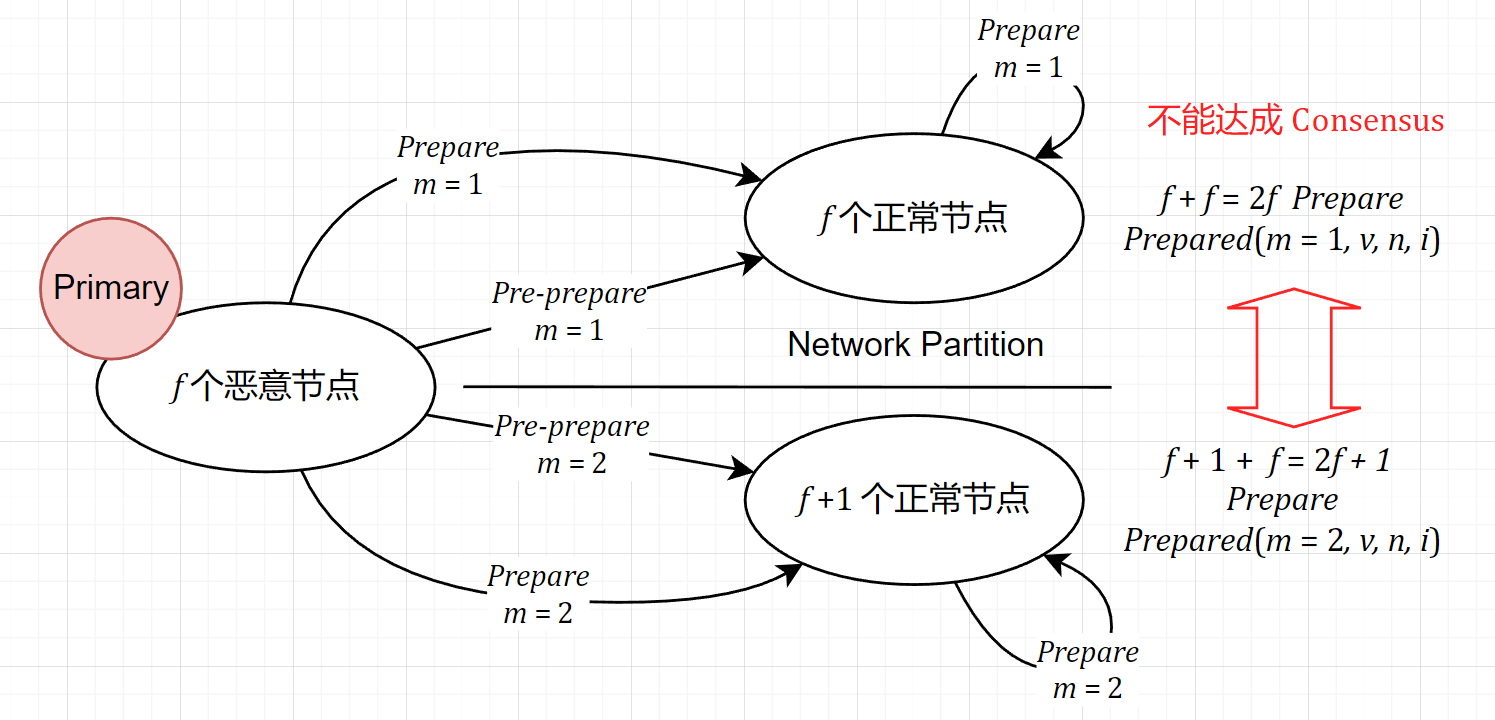
反例构造
首先我们可以构造一个如果只有 $2f$ 个 matching 就能打破上述原则的反例。
证明
接下来我们尝试用 Quorum 的思想来证明。使用反证法:如果每个节点都有 $2f+1$ 个 matching,但是最后仍然出现了两个 Replica $a \neq b$,使得
$$
prepared(m, v, n, a) \land prepared(m', v, n, b) \land D(m) \neq D(m')
$$
根据题设,有 $2f+1$ 个节点向 $a$ 发送了 $\langle Prepare, v, n, d, i \rangle _{\sigma_i}$,有 $2f+1$ 个节点向 $b$ 发送了 $\langle Prepare, v, n, d', i \rangle _{\sigma_i}$。根据容斥原理,至少有
$$
2 \times (2f + 1) - (3f+1) = f + 1
$$
个节点向 $a, b$ 分别发送了不同的消息。这样的行为毫无疑问是 malicious 的,所以至少存在 $f+1$ 个恶意节点,与至多有 $f$ 个恶意节点的协议假设矛盾。证毕。
Commit Phase 的必要性
Commit Phase 能够保证什么?
首先,Commit Phase 是 View Change 的副产物。后面的章节会详细解释 View Change,在这个阶段我们只需要知道 View Change 用来解决 Primary 作恶时的 Liveness 问题。而 Commit Phase 就是用来解决 View Change 过程中 Safety 的问题,即在 View 切换的前后:
- 一个 Sequence Number 对应的 Message 必定在所有正常节点之间达成 Consensus
- 不会出现一部分节点 Commit 了,但是另一部分节点完全不知道这件事,并继续执行下一个 Commit 或者重复使用 Sequence Number 的情况。
- 更加明确一点就是原文中的表达:
$$
Committed(n, m, v, i) \Rightarrow \lnot Committed(n, m', v', j), \forall D(m) \neq D(m'), v' > v
$$
反例构造
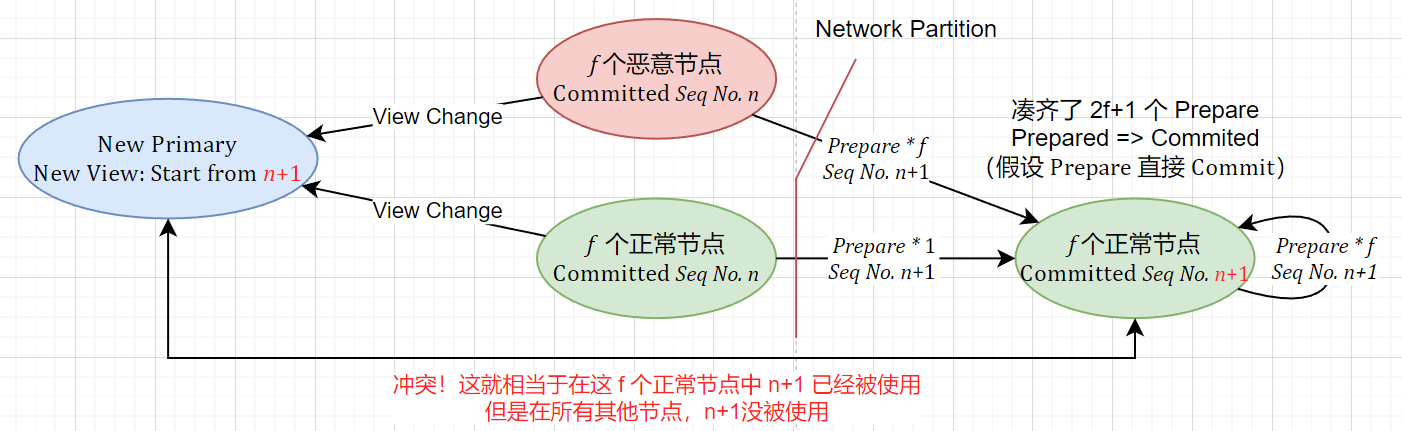
现在我们假设 Commit Phase 不存在,即在节点达成 Prepared 的时候就直接给 Client 发送 Reply。考虑下图的情况:
可以发现反例非常容易构造,我们甚至构造出了 $f$ 个节点使用了 $n+1$ 的 Sequence Number,但是剩余节点以及 New Primary 没有的情况。
理解
从上面这个例子已经可以看出,Commit Phase 主要就是需要保障一个 Sequence Number 在跨 View 的时候不能被 Malicious Primary 或者 Network Partition 影响,使得被重复使用,破坏 Safety。
增加一个 Commit Phase 的主要功能,就是 只有在知道有一定数量的其他 Replica 已经处于 Prepared 状态之后再进行 Commit,这个数量一定要保证能够在 View Change 的时候至少有一个节点能够证明这个请求已经 Prepared。
因为注意到上图:在节点 Commit 的时候,很多节点没有达到 Prepared 状态,无法在 Network Partition 的时候提供证据向新的 Primary 证明这个请求已经被 Commit。综上所述,这就是 Commit Phase 存在的意义。
为什么达成 Committed 状态需要 $2f+1$ 个 Prepared
估算
上一节提到,在 Commit 前,我们至少要保证有足够多的 Replica 已经处于 Prepared 阶段,使得在 Network Partition 出现的时候仍然能够向 Primary 提供信息,告诉 Primary 一个请求已经被 Commit。那这个数量到底应该是多少呢?通过简单的估算其实就可以得到。
已知 New Primary 需要 $2f$ 个除了自己以外的 View Change 请求。最悲观地考虑,出现了最大限度的 Network Partition,即有 $f$ 个节点无法通信。在这个极限情况下的极限情况是这 $f$ 个 Replica 都处于 Prepared 状态却无法与 Primary 通信。而其余 $2f+1$ 个节点中又有 $f$ 个 malicious node,可以假装不知道自己 Prepared 了。
所以,在那 $2f+1$ 个节点中至少需要 $f+1$ 个节点处于 Prepared 状态才能保证 New Primary 收到 Commit 记录,再算上 Network Partition 的 $f$ 个 Replica,一共得有 $2f+1$ 个节点处于 Prepared 状态才能保证信息能够在 Network Partition 和 View Change 的情况下送达 New Primary。
反例构造
上述文字选取的是极端情况,有一条不成立即为反例。所以 $2f$ 个 Prepared 却仍然失败的反例和没有 Commit Phase 一样非常好构造,这里不再赘述。
为什么 New Primary 需要 $2f$ 个 View Change
理解了 Commit Phase 的 $2f+1$ 便不难发现,这里 $2f$ 这个数目的选取是和 Committed 数目的选取是相关的。
两个 $2f+1$ (实际上 View Change 算上 New Primary 也是 $2f+1$) 在总共 $3f+1$ 的池子里,Intersection (Quorum) 的大小总是不小于 $f+1$ 个 Replica 的。这样就保证了总有一个 Non-faulty Replica 位于最终的 Quorum 当中(faulty replica 可以隐瞒不报,装作不知道,所以一定需要 non-faulty replica),即既是 Prepared,又没有被 Network Partition 和 Malicious Replica 影响到。
为什么 Reply 需要 $f+1$ 个 Matching
这个就非常 Intuitive 了,因为这样必定能有一个 Non-faulty Replica 回复。
Checkpoint (Garbage Collection) 的必要性
注意到 View Change 的时候需要附上所有的记录来证明自己是正常节点,这所带来的开销随着时间的推移显然是不可接受的,所以我们需要想办法回收一部分 log。
Checkpoint 为什么在数字签名模式下只需要 $f+1$?
因为 $f+1$ 保证了至少有一个 Non-faulty Node 进行了 Checkpoint,也就是在没有 Network Partition 的情况下必定可以从网络中访问到这个 Checkpoint。
但是这里其实有一个问题:如果 Network Partition 了呢?注意到 PBFT 只在没有 Network Fault 的情况下 Guarantee Liveness,所以在那种情况下,需要请求 Checkpoint 的节点就 In-dark 了。如果这样的情况足够多,Liveness 也就无法保证了。
View Change 和 Liveness 之间的关系
View Change 主要是为了解决没有 Network Fault 的情况下的 Liveness 问题。当一个 Replica 的请求迟迟无法完成的时候就会 Trigger View Change。因为请求无法完成无非几种情况:
- Primary 作恶,比方说只发给一部分 Replica Preprepare 消息
- Network Partition
View Change 在第二种情况下其实并不能解决问题,但是可以解决第一种情况的问题。这就是 View Change 的 Intuition。
Primary 作恶带来的 In-Dark 问题
注意到 Primary 可以故意不给某些节点发请求,即 Primary 作恶。在这种情况下,这些节点既不会触发 View Change,也不会做任何事情,也就是字面意义上的 In-Dark。
由于前面的论证,PBFT 已经保证了 Safety,同时在没有 Network fault 的情况下也保证了 Liveness,所以这样的 In-Dark 并不会有什么特别大的影响。
只有当 In-Dark Replica 的数量多到使得 Consensus 无法达成了,才会 trigger View Change,使得协议能够推进下去。
Network Recovery 的流程
- 首先向网络请求 Checkpoint
- 如果能顺利 Catch Up,那就无缝衔接
- 反之,迎来的结果必然是请求积压无法处理,timeout 之后便会 Request View Change,然后在 View Change 的过程中完成 Catch Up
Misc
- Q: 如果 Primary 无中生有虚构信息或者篡改 Client 信息怎么办?
- A: 注意到 $\langle Request, o, t, c \rangle _{\sigma_c}$ 的角标 $\sigma_c$,客户端签名保证了 Primary 不能篡改消息也不能伪造消息。
- Q: 如果 Client 不知道当前的 Primary 怎么办?
- A: 如果客户端一段时间内没有收到 Reply,触发 Timeout,重新 Multicast 请求。
- Q: 如果因为 Network Partition 正常节点没有把回复送达到 Client,Client 认为请求失败,重传怎么办?这不就等于会执行两次了吗?
- A: 注意到 $\langle Request, o, t, c \rangle _{\sigma_c}$ 中的 timestamp 可以解决这个问题
其他小的点:
- View Change 后面 New View 这里应该也是有 Time out 机制的,否则 New Primary 迟迟不发 New View 的话 Liveness 就寄了
- Client 发请求之后应该也有 Timeout 机制然后 Multicast,用来规避:(1)Primary 作恶,故意不发 Preprocess(2)发送的 Replica 不是 Primary
3 条评论
这绝对是我看过 PBFT F&Q 写得最详细的博客了 ,?
这绝对是我看过 PBFT F&Q 写得最详细的博客了 ,?
谢谢支持